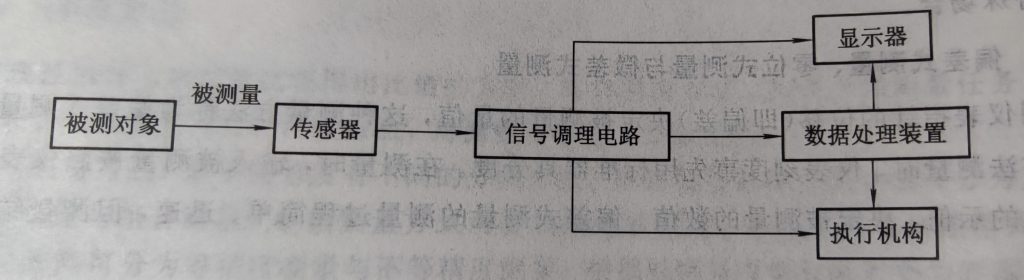
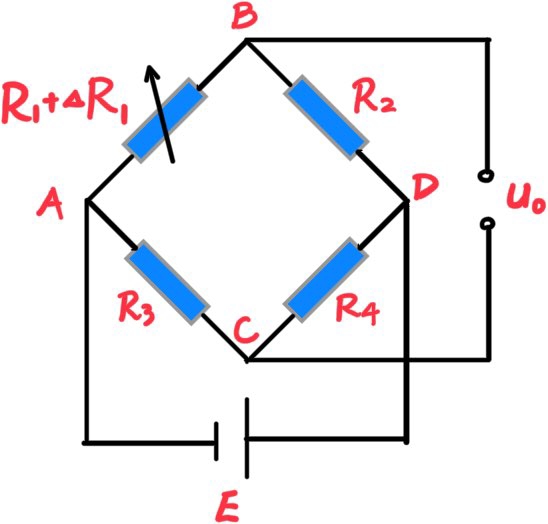
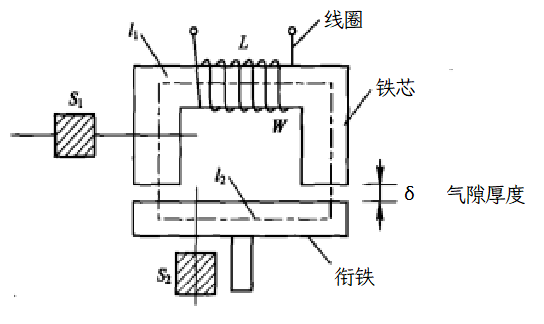
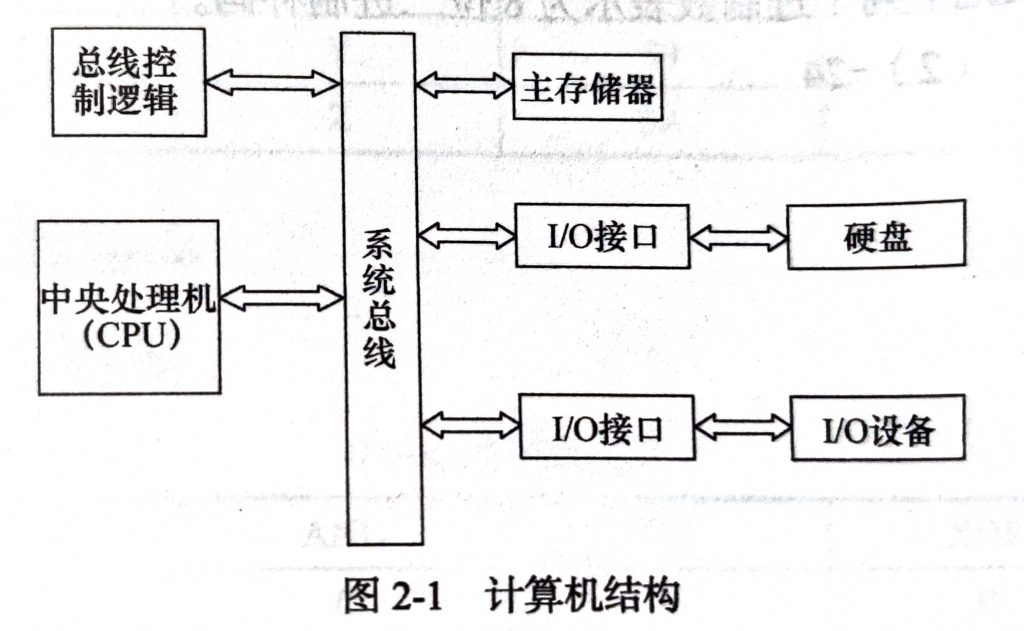
RSSI(Radio Signal Strength Indicator) 定位算法基于接收信号强度,将信号强度转换为距离,然后根据距离计算位置。
TOA(Time of Arrival) 定位算法基于信号传播速度,根据信号传播时间计算距离,然后根据距离计算位置。
TDOA(Time Difference of Arrival) 定位算法基于信号传播速度,根据信号传播时间差计算距离,然后根据距离计算位置。
AOA(Angle of Arrival) 定位算法基于到达角定位机制,通过测量信号的方向,多点定位。(两条线的交点)
距离无关的定位算法
质心定位算法
凸规划定位算法
典型定位算法
Active Badge 定位算法
Active Office 定位算法
Cricket 定位算法
WSN 中存在的隐藏终端和暴露终端问题(书上未找到)
“隐藏终端”(Hidden Stations):在通信领域,基站 A 向基站 B 发送信息,基站 C 未侦测到 A 也向 B 发送,故 A 和 C 同时将信号发送至 B,引起信号冲突,最终导致发送至 B 的信号都丢失了。”隐藏终端”多发生在大型单元中(一般在室外环境),这将带来效率损失,并且需要错误恢复机制。当需要传送大容量文件时,尤其需要杜绝”隐藏终端”现象的发生。
由于 ad hoc 网络具有动态变化的网络拓扑结构,且工作在无线环境中,采用异步通信技术,各个移动节点共享同一个通信信道,存在信道分配和竞争问题;为了提高信道利用率,移动节点电台的频率和发射功率都比较低;并且信号受无线信道中的噪声、信道衰落和障碍物的影响,因此移动节点的通信距离受到限制,一个节点发出的信号,网络中的其它节点不一定都能收到,从而会出现“隐藏终端”和“暴露终端”问题。
隐藏终端和暴露终端问题对 ad hoc 网络的影响:
隐藏终端”和“暴露终端”的存在,会造成 ad hoc 网络时隙资源的无序争用和浪费,增加数据碰撞的概率,严重影响网络的吞吐量、容量和数据传输时延。在 ad hoc 网络中,当终端在某一时隙内传送信息时,若其隐藏终端在此时隙发生的同时传送信息,就会产生时隙争用冲突。受隐藏终端的影响,接收端将因为数据碰撞而不能正确接收信息,造成发送端的有效信息的丢失和大量时间的浪费(数据帧较长时尤为严重),从而降低了系统的吞吐量和量。当某个终端成为暴露终端后,由于它侦听到另外的终端对某一时隙的占用信息,而放弃了预约该时隙进行信息传送。其实,因为源终端节点和目的终端节点都不一样,暴 露终端是可以占用这个时隙来传送信息的。这样,就造成了时隙资源的浪费。
下列属性中,用于设置线性布局方向的是(A)。 A. orientation B. gravity C. layout gravity D. padding
下列选项中,不属于 Android 布局的是(C)。 A. FrameLayout B. LinearLayout C. Button D. RelativeLayout
帧布局 FrameLayout 是将其中的组件放在自己的(A)。 A. 左上角 B. 右上角 C. 左下角 D. 右下角
对于 XML 布局文件,android:layout_width 属性的值不可以是(D)。 A. match_parent B. fill_parent C. wrap_content D. match_content
下列关于 RelativeLayout 的描述,正确的是(C)。 A. RelativeLayout 表示绝对布局,可以自定义控件的 x、y 的位置 B. RelativeLayout 表示帧布局,可以实现标签切换的功能 C. RelativeLayout 表示相对布局,其中控件的位置都是相对位置 D. RelativeLayout 表示表格布局,需要配合 TableRow 一起使用
AlertDialog 对话框能够直接通过 new 关键字创建对象。× 要通过 Builder 对象。
Toast 是 Android 系统提供的轻量级信息提醒机制,用于向用户提示即时消息。√
ListView 列表中的数据是通过 Adapter 加载的。√
二、选择题
在 XML 布局中定义了一个 Button, 决定 Button 按钮上显示文字的属性是(B) A. android:value B. android:text C. android:id D. android:textvalue
下列选项中,(C)用于设置 TextView 中文字显示的大小。 A. android:textSize=”18″ B. android:size=”18″ C. android:textSize=”18sp” D. android:size=”18sp”
使用 EditText 控件时,当文本内容为空时,如果想做一些提示,那么可以使用的属性是(D)。 A. android:text B. android:background C. android:inputType D. android:hint
为了让一个 imageView 显示一张图片,可以通过设置的属性是(A)。 A. android:src B. android:background C. android: img D. android:value
下列关于 ListView 的说法中,正确的是(C) A. ListView 的条目不能设置点击事件 B. ListView 不设 置 Adapter 也能显示数据内容 C. 当教据超出能显示范围时,ListView 自动具有可滚动的特性 D. 若 ListView 当前能显示 10 条,一共有 100 条数据,则产生了 100 个 View
CheckBox 被选择的监听事件通常使用(B)方法。 A. setOnClickListener B. setOnCheckedChangeListener C. setOnMenuItemSelectedListener D. setOnCheckedListener
当使用 EditText 控件时,能够使文本框设置为多行显示的属性是(A)。 A. android:lines B. android:layout_height C. android:textcolor D. android:textsize
下列关于 AlertDialog 的描述,错误的是(A) A. 使用 new 关键字创建 AlertDialog 的实例 B. 对话框的显示需要调用 show() 方法 C. setPositiveButton() 方法是 用来设置确定按钮的 D. setNegativeButton() 方法是用来设置取消按钮的
下列选项中,不属于 Android 四大组件的是(C) A. Service B. Activity C. Handler D. ContentProvider
下列关于 Android 中 Activity 管理方式的描述中,正确的是(B) A. Android 以堆的形式管理 Activity B. Android 以栈的形式管理 Activity C. Android 以树的形式管理 Activity D. Android 以链表的形式管理 Activity
下列选项中,(B)不是 Activity 生命周期方法。 A. onCreate() B. startActivity() C. onStart() D. onResume()
下列方法中,(A)是启动 Activity 的方法。 A. startActivity() B. goToActivity() C. startActivityResult() D. 以上都是
下列关于 Intent 的描述中,正确的是(B) A. Intent 不能够实现应用程序间的数据共享 B. Intent 可以实现界面的切换,还可以在不同组件间直接进行数据传递 C. 使用显式 Intent 可以不指定要跳转的目标组件 D. 隐式 Intent 不会明确指出需要激活的目标组件,所以无法实现组件之间的数据跳转
下列关于 SharedPreferences 存取文件的描述中,错误的是(C)。 A. 属于移动存储解决方式 B. SharedPreferences 处理的就是 key-value 对 C. 读取 xml 的路径是 /sdcard/shared_prefs D. 文本的保存格式是 xml
下列选项中,不属于 getSharedPreferences 方法的文件操作模式参数是(B)。 A. Context.MODE_PRIVATE B. Context.MODE_PUBLIC C. Context.MODE_WORLD_ READABLE D. Context.MODE_WORLD_WRITEABLE
下列方法中,(B)方法是 shardPreferences 获取其编辑器的方法。 A. getEdit() B. edit() C. setEdit() D. getAll()
Android 对教据库的表进行查询操作时,会使用 SQLietDatabase 中的(C)方法。 A. insert() B. execSQL() C. query() D. updata()
下列关于 SQLite 数据库的描述中,错误的是(C) A. SqliteOpenHelper 有创建数据库和更新数据库版本的的功能 B. SqliteDatabase 类是用来操作数据库的 C. 每次调用 SqliteDatabase 的 getWritableDatabase 方法时,都会执行 SqliteOpenHelper 的 onCreate() 方法 D. 当数据库版本发生变化时,会调用 SqliteOpenHelper 的 onUpgrade() 方法更新数据库
下列初始化 SharedPreferences 的内代码中,正确的是(D) A. SharedPreferences sp = new SharedPreferences(); B. SharedPreferences sp = SharedPreferences.getDefault(); C. SharedPreferences sp = SharedPreferences.Factory(); D. SharedPreferences sp = getSharedPreferences();
第六章 内容提供者和内容观察者
6.1 内容提供者
A 程序通过 ContentProvider 来暴露数据,B 程序通过 ContentResolve 操作 A 程序暴露的数据。A 程序会将操作结果返回给 ContentResolver,然后 ContentResolver 再将操作结果返回给 B。
如果一个应用程序想要访问另外一个应用程序的数据库,那么需要通过(C)实现。 A. BroadcastReceiver B. Activity C. ContentProvider D. AIDL
下列方法中,(B)能够得到 ContentResolver 的实例对象。 A. new ContentResolver() B. getContentResolver() C. newInstance() D. ContentUris.newInstance()
自定义内容观察者时,需要继承的类是(B)。 A. BaseObserver B. ContentObserver C. BasicObserver D. DefalutObserver
对查询手机系统短信时,内容提供者对应的 Uri 为(C)。 A. Contacts.Photos.CONTENT_URI B. Contacts.People.CONTENT_URI C. content://sms/ D. Media.EXTERNAL_CONTENT_URI
下列关于 ContentProvider 的描述,错误的是(D)。 A. ContentProvider 是一个抽象类,只有继承后才能使用 B. ContentProvider 只有在 AndroidManifest.xml 文件中注册后才能运行 C. ContentProvider 为其他应用程序提供了统一的访问数据库的方式 D. 以上说法都不对
关于广播类型的说法,错误的是(BC)。(多选) A. Android 中的广播类型分有序广 播和无序广播 B. 无序广播是按照一定的优先级进行接收 C. 无序广播可以被拦截,可以被修改数据 D. 有序广播按照一定的优先级进行发送
广播作为 Android 组件间的通信方式,使用的场景有(ABCD)。(多选) A. 在同一个 APP 内部的同一组件内进行消息通信 B. 不同 APP 的组件之间进行消息通信 C. 在同一个 APP 内部的不同组件之间进行消息通信(单个进程) D. 在同一个 APP 具有多个进程的不同组件之间进行消息通信
如果通过 bindService 方式开启服务,那么服务的生命周期是(C)。 A. onCreate() →onstart() →onBind() →onDestroy() B. onCreate() →onBind() →onDestroy() C. onCreate() →onBind() →onUnBind() →onDestroy() D. onCreate() →onStart() →onBind() →onUnBind() →onDestroy()
下列关于 Service 服务的描述中,错误的是(D) A. Service 是没有用户可见的界面,不能与用户交互 B. Service 可以通过 Context.startService() 来启动 C. Service 可以通过 Context.bindService() 来启动 D. Service 无须在清单文件中进行配置
下列关于 Service 的方法描述,错误的是(D)。 A. onCreate() 表示第一次创建服务时执行的方法 B. 调用 startService() 方法启动服务时执行的方法是 onStartCommand() C. 调用 bindService() 方法启动服务时执行的方法是 onBind() D. 调用 startService() 方法断开服务绑定时执行的方法是 onUnbind()