
第一章 绪论
1.1 数据库系统概述
1.1.1 四个概念
- 数据(Data)描述事物的符号记录 是 数据。数据含义 是 数据语义。
- 数据库(DB,DataBase)长期储存在计算机内,有组织的,可共享的大量数据的集合。特点:
- 按一定的数据模型组织、描述和储存。
- 较小冗余度。
- 较高数据独立性和易扩展性。
- 可共享。
- 数据库管理系统(DBMS,DataBase Management System)用户与操作系统间的一层数据管理软件,是计算机的基础软件。功能:
- 数据定义
- 数据组织、存储、管理
- 数据操纵
- 数据库事务管理和运行管理
- 数据库建立和维护
- 数据库系统存储、管理、处理和维护数据的系统。
1.1.2 历程
- 人工管理阶段
- 文件系统阶段
- 数据库系统阶段
1.1.3 数据库系统的特点
- 数据结构化
- 数据共享性高、冗余度低、易扩充
- 数据独立性高
- 数据 由 数据管理系统 统一管理控制
1.2 数据模型
对数据特征的抽象。
是数据库系统的核心和基础
根据模型应用目的可以将模型分为两大类:
- 概念模型
- 逻辑模型和物理模型
1.2.1 概念模型
基本概念:
- 实体客观存在并可相互区别的事物称为 实体 。一条数据本身是一个实体。
- 属性实体具有的某一特性称为 属性。
- 码唯一标识实体的属性集称为 码。
- 实体型实体名和属性名集合来抽象刻画实体,称为 实体型。如 学生(姓名,学号,性别,出生日期)是一个实体型。
- 实体集同一类型的实体集合。
- 联系不同实体集之间的联系。有一对一,一对多,多对多。
E-R 方法:实体-联系方法。
1.2.2 数据模型的组成要素
- 数据结构数据库的组成对象以及对象之间的联系。
- 数据操作操作及操作规则。对各种对象的实例允许执行的操作的集合。
- 数据的完整性约束条件一组完整性规则。
1.2.3 常用数据模型
- 层次模型
- 网状模型
- 关系模型
- 面向对象数据模型
- 对象关系数据模型
- 半结构化数据模型
基本层次联系 是指两个记录以及它们间的一对多(包括一对一)的联系。
1.2.4 数据模型详解
层次模型
特点:
- 有且只有一个结点没有双亲节点,称为根节点
- 根以外其它结点有且只有一个双亲节点
//类似树,只有一个父节点但可以很多个子节点。
优点:
- 数据结构简单清晰
- 查询效率高
- 良好的完整性支持
缺点:
- 非层次性的不适合用层次模型表示
- 具有多个父节点的关系,使用层次模型比较复杂
- 查询子女结点必须通过双亲节点
- 层次命令趋于程序化
网状模型
特点:
- 允许一个以上的节点无双亲
- 一个结点可以有多个双亲
优点:
- 更直接描述现实世界
- 性能良好,存取效率高
缺点:
- 结构复杂
- 嵌入高级语言后,用户不易掌握
- 必须了解系统结构的细节
关系模型
数据结构
- 关系:一张表
- 元组:一行
- 属性:一列
- 码:唯一标识
- 域:属性的取值范围
- 分量:元组的一个属性值
- 关系模式:对关系的描述,理解成表头,但表示成关系名(属性1,属性2,属性3,……)
关系模型要求关系规范化,不允许表中有表。
术语对比
| 关系术语 | 一般表格的术语 |
|---|---|
| 关系名 | 表名 |
| 关系模式 | 表头 |
| 关系 | 一张表 |
| 元组 | 行 |
| 属性 | 列 |
| 属性名 | 列名 |
| 属性值 | 列值 |
| 分量 | 一条记录中的一个列值 |
| 非规范关系 | 表中有表 |
优点:
- 建立在严格的数学概念上
- 数据结构简单、清晰,用户易懂、易用
- 存取路径对用户透明
1.3 数据库系统的三级模式结构
外模式、模式、内模式 三个抽象级别。
- 模式也称 逻辑模式 ,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。
- 外模式也称 子模式 或 用户模式 ,它是数据库用户能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。
- 内模式也称 存储模式 ,一个数据库只有一个内模式,它是数据物理结构和存储方式的描述。是数据在数据库内部的组织方式。
1.4 数据库系统的二级映像功能与数据独立性
两层映像:
- 外模式 / 模式映像一个模式(数据的全局逻辑结构)可以有多个外模式(数据的局部逻辑结构)。注:应用程序是根据数据的外模式编写的。数据与程序有逻辑独立性。模式改变时,外模式可以不变。
- 模式 / 内模式映像当存储结构改变时,模式和应用程序都可以不改变。数据与程序具有物理独立性。
第二章 关系数据库
2.1 关系数据结构及形式化定义
2.1.1 关系
- 域属性的取值范围。定义:域是一组具有相同数据类型的值的集合。域允许的不同取值个数称为 基数。
- 笛卡尔积就是把多个域的全部组合遍历。例如 老师域×学生域 得到 全部(老师,学生)。
- 关系笛卡尔积代表全部的可能性,但现实中往往并不是全部可能性都真实存在。因此笛卡尔积的子集称为关系。若某一属性组的值能唯一地标识一个元组,而其子集不能,则称该属性组为 候选码 。多个候选码,选一个为 主码 。候选码的各种属性称为 主属性 。不包含在各种候选码中的属性称为 非主属性 或 非码属性 。候选码有时候只有一个属性,有时候可能包含全部属性,即全部属性才能唯一地标识一个元组。后者称为 全码 。三种类型:
- 基本关系(基本表,基表)
- 查询表
- 视图表
- 列是同质的,每个分量来自同一个域。
- 不同的列可以出于同一个域。如 老师域和学生域 合成 人域。但属性名(列名)需要区分开。
- 列的顺序无所谓。
- 行的顺序无所谓
- 任意两个元组的候选码不同。(候选码是唯一标识)
- 分量必须取原子值。即每个分量都是一个不可分的数据项。(基本)
2.2 关系的完整性
实体完整性、参照完整性、用户定义的完整性。
- 实体完整性主属性不能取空值。
- 参照完整性外码对于关系 R 中每个元组,外码要么取空,要么取外码所在表的主码(唯一标识)。
- 用户定义的完整性例如分数在0~100之间。
2.3 关系代数
传统集合运算:
- 并 R ∪ S
- 差 R – S 属于R但不属于S
- 交 R ∩ S
- 笛卡尔积 ×
关系运算
- 选择 Sigma σF(R)选择满足条件的元组。
- 投影 派 ΠA(R)关系 R 的投影是从 R 中选择出若干属性列,组成新的关系。
- 连接 $$
R \Join S
$$
从两个 关系 的笛卡尔积中选取满足条件的元组。 - 除运算 R ÷ S 包含所有在 R 不在 S 的属性和值。
2.4 关系演算
ALPHA 语言
GET 检索操作
- GET W(SC.Cno) //条件为空
- GET W(5)(Student.Sno,Student.Sage):Student.Sdept=‘IS’ DOWN Student.Sage //取五个 IS 系学生的学号年龄,年龄降序排列。
PUT 插入操作
HOLD 取指令,类似于指针指向一个关系
UPDATE 修改操作,不允许修改主码
DELETE
DROP
基本格式
操作语句 工作空间名(数量)(表达式):操作条件
RANGE A B 把 A 重命名为 B 。
| 函数名 | 功能 |
|---|---|
| COUNT | 对元组计数 |
| TOTAL | 求总和 |
| MAX | 求最大值 |
| MIN | 求最小值 |
| AVG | 求平均值 |
QBE 语言
Query By Example。
在表中填条件。
操作符
| 操作符 | 意义 |
|---|---|
| P. | Print 打印 |
| U. | Update 更新 |
| I. | Insert 插入 |
| D. | Delete 删除 |
第三章 SQL
3.1 概述
特点:
- 综合统一
- 高度非过程化
- 面向集合的操作方式
- 同一种语法结构提供多种使用方式
- 语言简洁,易学易用
数据库中只存放视图定义,不存放视图数据。
3.2 SQL 语句
操作关键字:
| 关键字 | 作用 |
|---|---|
| CREATE | 创建 |
| DROP | 删除表,索引 |
| ALTER TABLE | 修改 |
| UPDATE | 更新 |
| DELETE | 删除数据 |
ALTER TABLE 适用于表和索引的修改,可以ADD列,DROP列,ALTER列
名词关键字:
| 关键字 | 意义 |
|---|---|
| SCHEMA | 模式 |
| TABLE | 表 |
| INDEX | 索引 |
数据类型:(挖坑,下辈子填)
SELECT 语句中可选的条件:
| 关键字 | 作用 |
|---|---|
| DISTINCT | 去除重复 |
| ALL | 不去除重复 |
通配符:
- % 任意长度
- _ 一位长度
WHERE 子句常用查询条件:
3.3 索引(INDEX)
索引存在可以加快查询速度。
3.4 视图(VIEW)
CREATIVE VIEW name (列名1,列名2…) AS SELECT [WITH CHECK OPTION];
第四章 数据库安全性
4.1 安全性概述
安全性:保护数据库以防止不合法的使用所造成的数据泄露、更改或破坏。
不安全因素:
- 非授权用户对数据库恶意存取破坏
- 数据库的重要或敏感的数据被泄露
- 安全环境的脆弱性
4.2 安全性控制
常用方法和技术:
- 用户标识和鉴别
- 存取控制
- 视图机制
- 审计
- 数据加密
- 用户身份鉴别
- 静态口令
- 动态口令
- 生物特征
- 智能卡
- 存取控制
- 定义用户权限
- 合法权限检查
- 自主存取控制两个要素:
- 数据库对象
- 操作类型
- 授权
- 授予 GRANTGRANT 操作如SELECT ON TABLE name TO username;
- 收回 REVOKEREVOKE 操作如SELECT ON TABLE name TO username;
- 强制存取控制方法强制存取控制是对数据本身进行密集标记。无论数据如何复制,标记和数据是一个不可分的整体。只有符合密级标记要求的用户才可以操纵数据,从而提供了更高级别的安全性。数据库所管理的实体被分为主体和客体。客体受主体操控。可以理解成,主体是操作者,客体是资料。敏感度标记分配给主体与客体的实例值。主体:许可证级别。客体:密级。敏感度标记:
- 绝密
- 机密
- 可信
- 公开
- 主体许可证级别高于等于客体密级则可读
- 主体许可证级别低于等于客体密级则可写
第五章 数据库完整性
指 正确性和相容性。
5.1 实体完整性
主码不能取空值。
定义实体完整性(设置主码)
- 列级定义(单属性)
- 表级定义(单属性或多属性)
检查实体完整性
- 检查主码值是否唯一
- 检查主码的各个属性是否为空
5.2 参照完整性
外码对于关系 R 中每个元组,外码要么取空,要么取外码所在表的主码(唯一标识)。
定义参照完整性(设置外码)
表级定义。
FOREIGN KEY (属性名) REFERENCES 表名(属性名)
检查参照完整性
5.3 用户定义的完整性
如列值非空,列值唯一,列值是否满足一个条件表达式 CHECK(列名 条件)。
- 列级定义
- 元组上定义
第六章 关系数据理论
6.1 函数依赖
X→Y则函数依赖。
通过X可以推出Y。
6.2 码
候选码
主码
主属性:包含在任何一个候选码中的属性。
其它叫非主属性。
码:候选码和主码统一简称。
6.3 范式
关系数据库中的关系是要满足一定要求的,满足不同程度要求的为不同范式。
最低要求 1NF。第一范式中,进一步要求为 2NF。
规范化:一个低一级范式的关系模式,通过模式分解可以转换为若干个高一级范式的关系模式的集合。
6.4 2NF
若R∈1NF,且每一个非主属性完全函数依赖于任何一个候选码,则R∈2NF。
6.5 3NF
没有传递依赖关系的存在称为3NF。
定义:设R<U,F>不存在 码X,属性组Y,非主属性Z,使得
$$
X\to Y,Y\to Z,Y\not{\to } X
$$
成立,则称 R<U,F>∈3NF。
第七章 数据库设计
7.1 基本步骤
- 需求分析
- 概念结构设计
- 逻辑结构设计
- 物理结构设计
- 数据库实施
- 数据库运行和维护
7.2 E-R 图
E-R 图是概念结构设计中的概念。
E-R 模型
两个实体型之间的联系:
- 一对一联系(1:1)
- 一对多联系(1:n)
- 多对多联系(m:n)
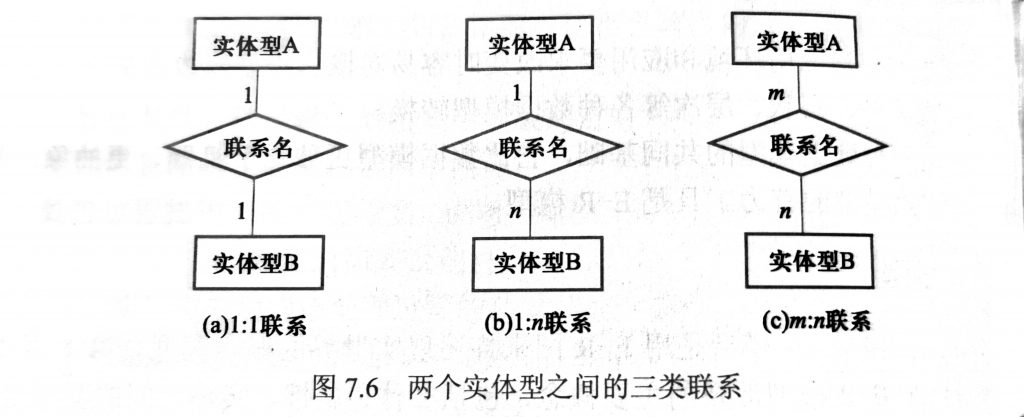
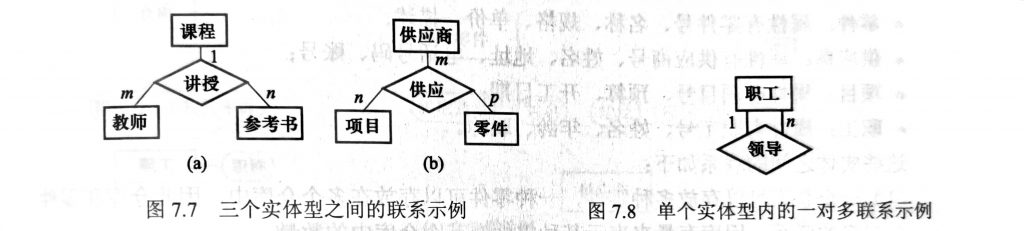
多个实体型之间的联系:
一对一,一对多,多对多。
单个实体型内的联系:
一对一,一对多,多对多。
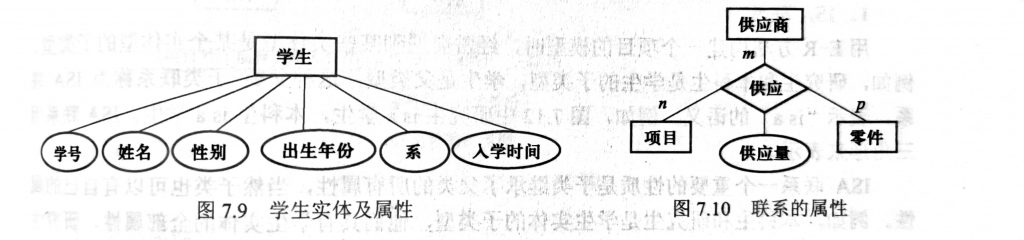
E-R 图
实体型:矩形
属性:椭圆
联系:菱形
第十章 数据库恢复技术
10.1 事务
定义
是用户定义的一个数据库操作序列。
这一系列操作,要不全都做,要不全都不做。是不可分割的。
特性
ACID 特性:
- 原子性(不可分割)
- 一致性(使数据库中的数据不发生逻辑错误)
- 隔离性(并发的各个事务之间不能相互干扰)
- 持续性(永久性,事务提交后,其改变或者效果应该是永久性的)
干扰因素:
- 不同事务交叉执行
- 事务执行时被强行停止
第十一章 并发控制
11.1 概述
事务是并发控制的基本单位。
并发操作带来的不一致性
- 丢失修改
- 不可重复读
- 读 “脏” 数据
主要原因:并发操作破坏了事务的隔离性。
并发控制机制就是要用正确的方式调度并发操作,使一个用户事务的执行不受其他事务的干扰。
并发控制主要技术:
- 封锁
- 时间戳
- 乐观控制法
- 多版本并发控制
11.2 可串行化调度
定义
多个事务的并发执行是正确的,当且仅当其结果与按某一次序串行执行这些事务时的结果相同。
可串行性
是并发事务正确调度的准则。
11.3 两段锁协议(2PL)
事务两个阶段:
- 获得封锁,扩展阶段:在对任何数据进行读、写操作之前,首先要申请并获得对该数据的封锁。
- 释放封锁,收缩阶段:在释放一个封锁之后,事物不再申请和获得任何其他封锁。
11.4 封锁的粒度
封锁对象的大小。
封锁对象可以是逻辑单元,也可以是物理单元。
封锁粒度与系统的并发度和并发控制的开销密切相关。
多种封锁粒度,供不同的事务选择。称为多粒度封锁。